
![]()
![]()
![]()
![]()
![]()
Survey on graph databases for similarity-based retrieval
In the past few years, graph databases have outperformed other ones (e.g. tree and hash methods) regarding the similarity search problem. However, there are many variations of graph methods in the literature, such as kNN-based or SW-based, and previously there was no work that had evaluated important issues regarding scalability and parametrization. Thus, we performed a survey to better understand the differences of behaviors among several algorithms accross several datasets.
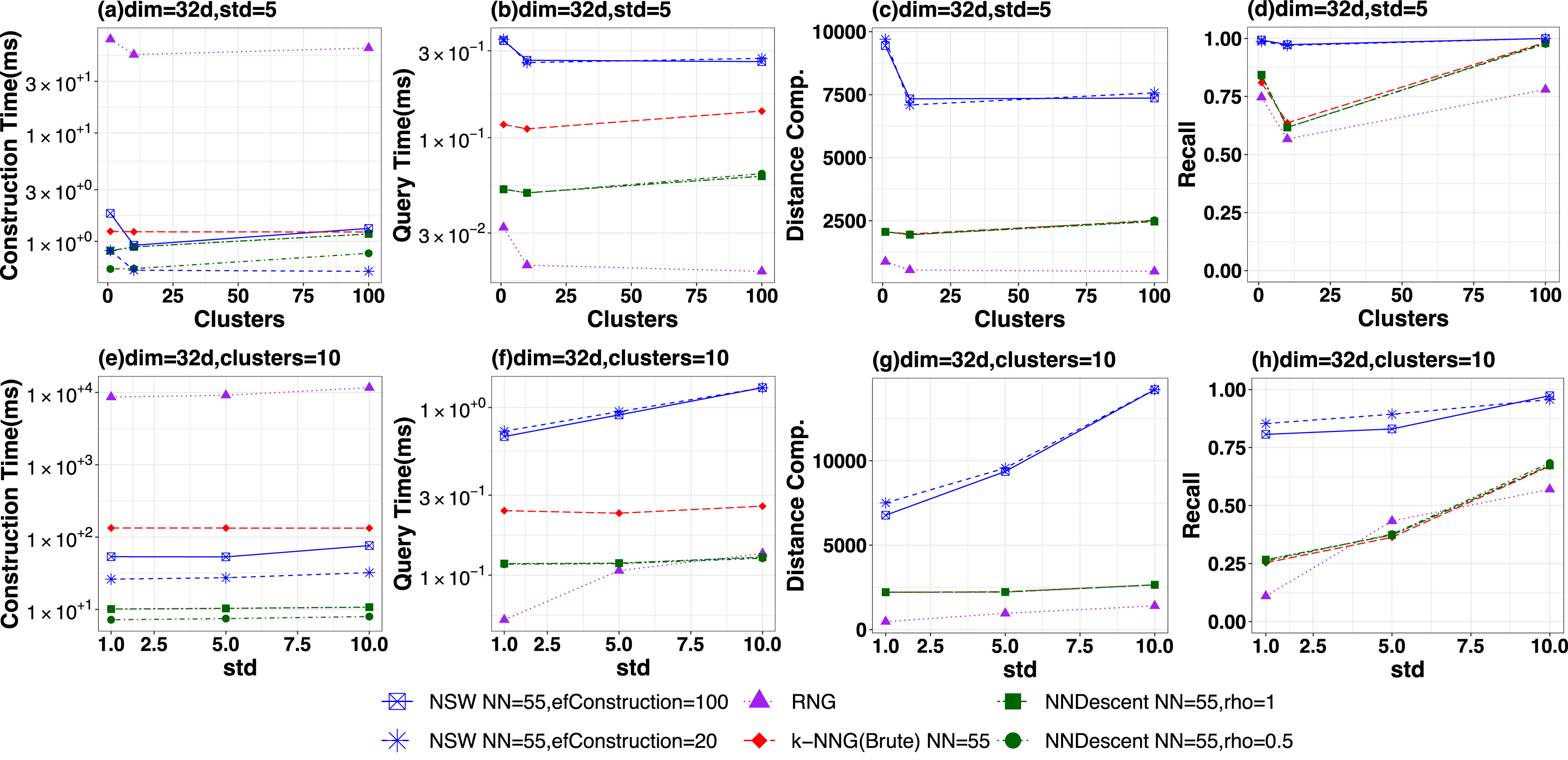
In this work, we addressed important points for understanding graph databases, such as:
- the scalability regarding cardinality and dimensionality of datasets
- query strategies (e.g. exact and approximate)
- trade-offs between the parameters for database construction (indexing) and querying
- which properties in the datasets affect the most each algorithm and parameters.
You can find the published research here.
Automated Selection of Graph Algorithms and their Parameters
In our previous survey, we concluded that selecting the best graph algorithm is not a trivial task, since each graph configuration might behave differently according to the datasets’ characteristics. Thus, we developed a recommender system based on meta-learning to automatically select the best algorithm and its set of parameters (including both index and query parameters). Find below the proposed pipeline for instantiating the recommender system.
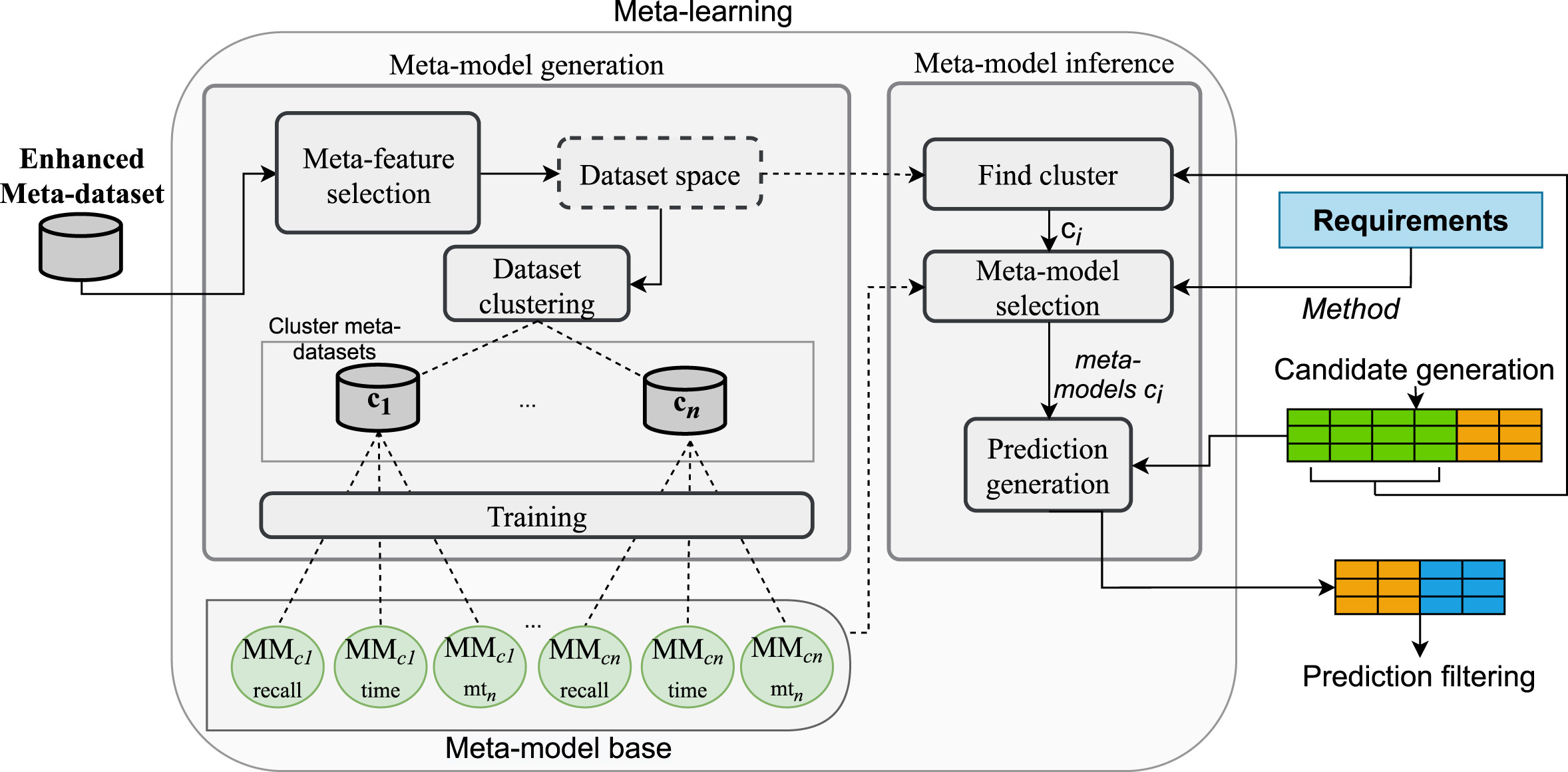
Meta-learning is the machine learning paradigm that aims at learning how to learn. In this work, we used meta-learning techniques to map several datasets’ characteristics into the performances achieved by different algorithm configurations. This way, when a new dataset is available, the recommender system is capable of analysing its underlying properties and automatically recommend a suitable algorithm configuration according to the user preferences. For instance, a user has might require a configuration that speeds up the queries without caring about the memory usage; or require the best precision possible with the lower query time possible. You can find the published research here.
During the development of this project, I developed a tool for characterizing different datasets. These characteristics are the so called meta-features, which meta-describe datasets. The repository for this tool can be found here. Furthermore, the whole pipeline for preprocessing the meta-features, performing a meta-training, and finally providing recommendations can be found here.